Knowledge Graph
Every SAP landscape is unique, shaped by years of custom development and configuration decisions.
Adri builds a Knowledge Graph of that unique landscape to make AI agents work for you.
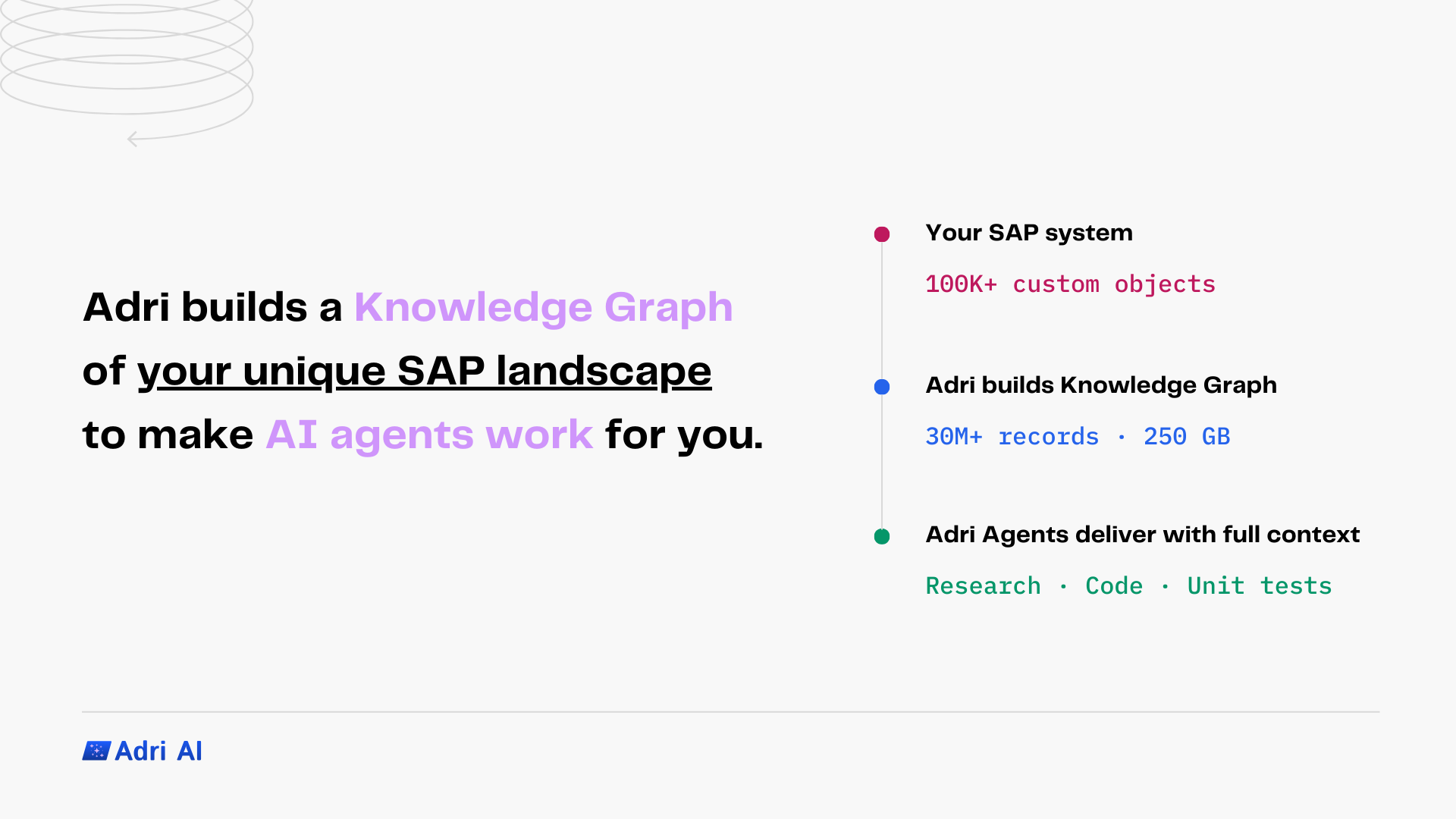
When you connect your SAP system with Adri, a dedicated Knowledge Graph is built. The Knowledge Graph is a structured representation of every custom object and their dependencies in a customer's SAP system.
This is what gives Adri agents system-level context: when you ask them to research, code, or write unit tests, they work with your tables, your enhancements, and your configuration.
What's in the Knowledge Graph
-
Every custom object and its relationship with other objects For example, which tables a function module reads from, which data elements a field uses, which programs an enhancement modifies.
-
Documentation that gives objects their business meaning For example, code documentation attached to objects, process flow & architecture diagrams, coding guidelines & development standards.
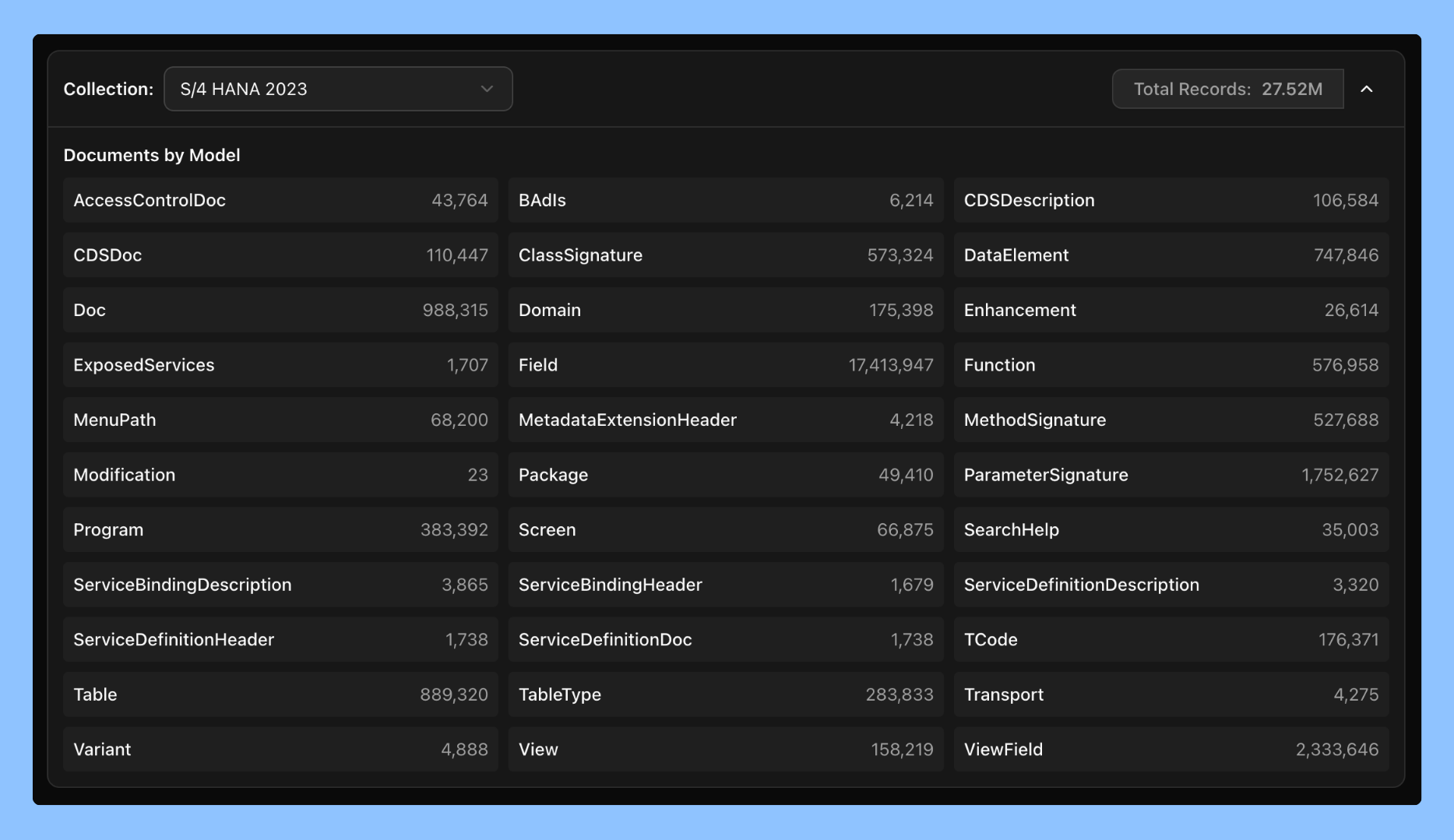
Here's what is included in the Knowledge Graph of a typical S/4HANA 2023 system:
How large is this Knowledge Graph?
For a typical S/4HANA 2023 system with 100,000 custom objects, the Knowledge Graph contains about 30 million records stored in roughly 250 GB of vector database storage.
Try the free demo sandbox to see large-scale knowledge creation and retrieval in action. The Knowledge Graph in this sandbox contains about 27 million objects for S/4HANA 2023 and 18 million objects for ECC 6.0.
How Adri Agents Use the Knowledge Graph
When you ask an Adri agent a question, it queries your Knowledge Graph using ChromaSQL. ChromaSQL is a specialized query language built by Adri AI.
Three types of search run behind the scenes:
- Semantic search: queries the Vector Database to find objects by meaning (e.g., "special stocks from vendor")
- Keyword search: queries Postgres for exact matches,
LIKEpatterns, and structured filters (by package, object type, transport request) - Large object retrieval: fetches oversized objects from S3 when needed
The agent uses results from these searches to give you answers grounded in what actually exists in your landscape.
How is the Knowledge Graph Built
The Knowledge Graph is built entirely within your VPC. Nothing reaches your SAP system from outside — the architecture is designed so that your SAP subnet never has inbound traffic.
-
Extract — The Adri Connector runs inside your SAP-restricted subnet. It reads ABAP objects from SAP Gateway via ADT APIs and pushes them outbound to the Knowledge Graph Builder. Your SAP subnet's "no inbound ports" policy stays intact.
-
Embed — The Knowledge Graph Builder converts ABAP content into vector embeddings via your cloud provider's LLM service (AWS Bedrock, Azure OpenAI, or GCP Vertex AI). All traffic goes through VPC endpoints — no public internet.
-
Store — The Builder distributes data across three storage tiers based on size: a vector database for embeddings (< 8 KB), Postgres for source code and metadata (< 1 MB), and S3 for oversized objects (> 1 MB). All within your VPC.
You control what ABAP content is sent for embedding: full source (best search quality), signatures only (method bodies stripped), or local embedding (nothing leaves your VPC). This can be configured per SAP system. See deployment architecture for details.
For the full infrastructure details — network zones, mTLS authentication, storage tier design, security boundaries — see the deployment architecture.
FAQs
Can I connect multiple SAP systems?
Yes. Any number of systems, any version (ECC, S/4HANA, etc.). A separate Knowledge Graph is built for each, so agents have system-specific context for every landscape in your environment.
What SAP products are supported?
ECC and S/4HANA today. Support for SuccessFactors, OpenText, and other SAP products and add-ons is coming.
Does the Knowledge Graph stay current?
Yes. When custom objects are created, modified, or deleted in your SAP system, the Adri Connector syncs changes to the Knowledge Graph.
The sync frequency is decided by the Basis team. We typically recommend running a background job weekly.
Can I control what data is included in the Knowledge Graph?
Yes. You configure a content scope per SAP system — full source code, signatures and documentation only, or local embedding only (no data leaves the VPC). See content scope options.